

This is part 1 in a series exploring lessons learned from my project Photosynthesis AI, in which I train reinforcement-learning agents to play the board game Photosynthesis.
I’ll assume a basic familiarity with RL but will clarify anything unusual along the way. More background on the algorithm, the custom environment, and the broader project is available on the project page.
Each post in this series looks at one design problem in depth. This first entry focuses on how to adapt single-agent RL libraries such as Stable Baselines 3 to multiplayer settings. Every instalment ends with a short design diary discussing current challenges and open questions from the project.
Problems with training agents for multiplayer games in Gymnasium and Stable Baselines 3
The two main ingredients for an RL system are the environment and the agent. The environment defines the state of the world, and the agent is the decision-maker trained with machine learning to choose from a set of actions to respond to the state, navigating their way through the environment to aim for a reward. The best agent is the one that chooses the actions that lead to the greatest reward, either at the end of the game or at intermediate points throughout it.
Gymnasium (a fork of the now unmaintained Gym) is one of the most popular libraries for defining environments for training RL models. It is often used in conjunction with the library Stable Baselines 3 (SB3), which defines the models and deals with the training procedure (propagating rewards back through episodes, applying temporal discounting, and so on). The basic code for training an agent is very simple.
First we define an environment. This is a class that inherits from gym.Env, and implements a reset method (to initialise a new episode), and a step function, that takes in an integer representing the action, and outputs a tuple of:
- New state vector :
np.ndarray - Reward :
float - Is the episode completed? :
bool - Is the episode truncated? :
bool - Additional info :
dict[Any, Any]
This is then passed to a pre-defined SB3 model as follows:
from stable_baselines3.ppo import PPO
env = MyCustomEnv()
agent = PPO("MlpPolicy")
agent.learn(total_timesteps=10_000)
Here is where the first problems start to arise. In RL, the environment vector is what is seen by the agent. That is to say, it is everything that the agent uses to make a decision. However, for multiplayer games, this breaks down.
Suppose there are four players in a game of poker. The environment vector should only contain the cards that are visible to the player. However consider the image below. If we get a state from the environment, return an action (e.g. the amount bet), then get the next state, then the agent is learning that making a bet will show you the next player’s cards!
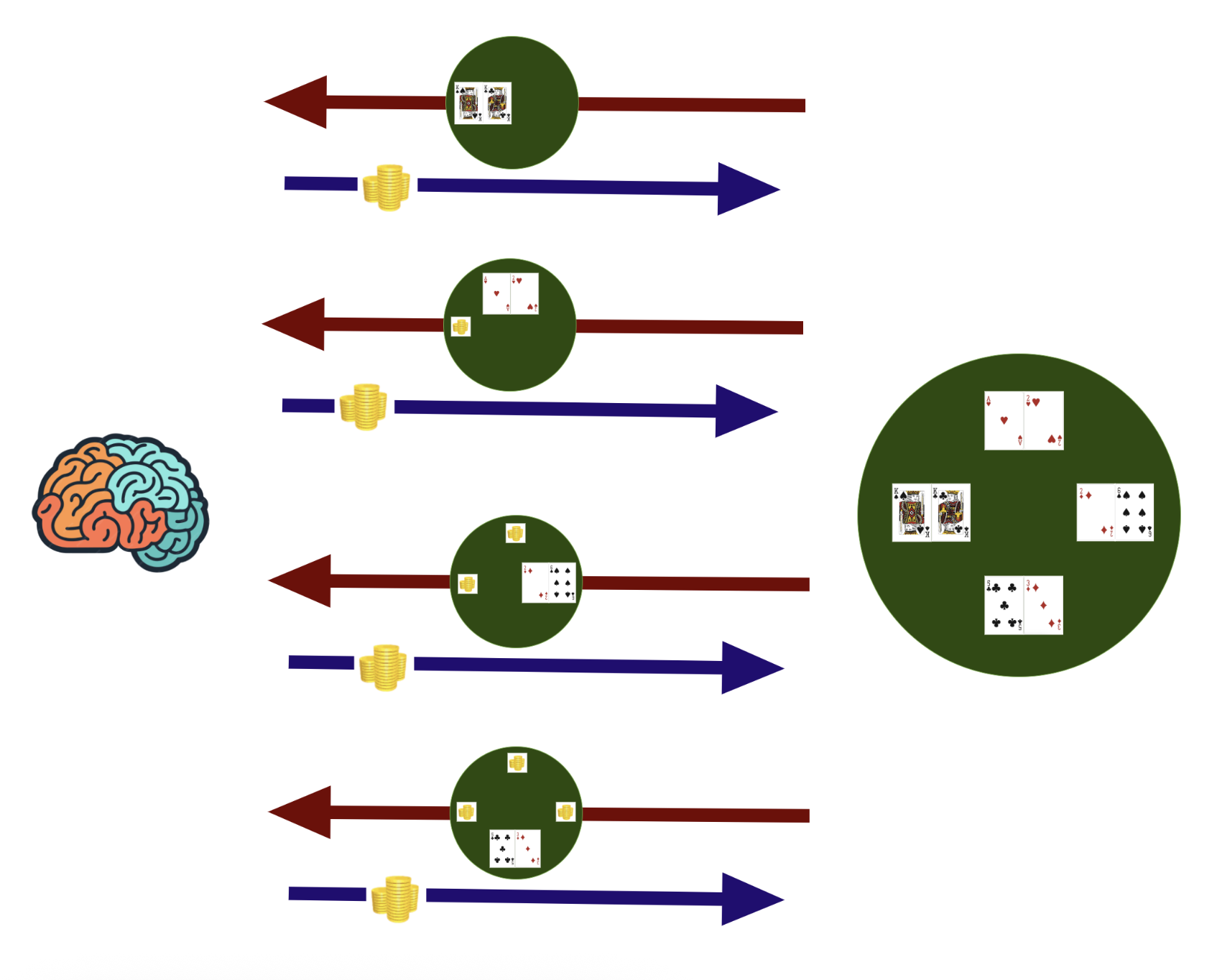
This is obviously wrong! We are leaking information that a real agent will not see.
An alternative is to train offline. To do this we can use a set of experience buffers, as shown in the image below.
Here, we use a frozen agent (i.e. one running only in inference mode) to generate the actions. The state from the perspective of player 1 is sent both to the agent (to ask for an action) and to buffer 1. The action is sent to the environment which generates a state, now from the perspective of player 2. This is sent to both the frozen agent and to buffer 2, and so on.
After the game has finished, we take the sequence of states in buffer 1, and compose them together into an episode (or episodes), along with the set of rewards granted to player 1. Similarly, the set of states in buffer 2 is composed into an episode or episodes.
Each episode is now a valid sequence of states from the perspective of a single player, and can be passed to the agent for training.
This approach works for off-policy algorithms such as ACER (Actor-Critic with Experience Replay), because they can learn from experiences stored in replay buffers rather than requiring trajectories sampled from the current policy. However, I wanted to use PPO (popular model Proximal Policy Optimisation), which is an on-policy method, and so cannot learn from an external buffer, at least in SB3.
To avoid data leakage while training on-policy, we need an environment that dynamically hides information from non-active players, which brings us to the idea of a masked, multi-agent wrapper.
Solution with masked environment
The solution that I have used with Photosynthesis AI, that is generally applicable to similar multiplayer games, is to use a masked environment. This is a wrapper layer that abstracts an environment. It hides private information from the learning agent and manages interactions between multiple internal agents. Only the active agent’s observations are ever exposed to the outer training loop. This ensures that it only ever sees states from its own perspective, allowing it to be trained in SB3 as if it was a single-player game.
Here, we define multiple agents. One is the active agent, that will undergo on-policy learning with all states that it receives.
The others will be frozen agents. Their policies are fixed and will not update during training. These will be subsumed along with the environment into a larger meta-environment, such that the meta-environment only returns states from the perspective of the active player. See the image below.
Here, the active agent receives a state and responds with an action. The meta-environment sends this to the environment, gets a new state, sends this to the first frozen agent, who sends an action, and so on. Only once the last frozen agent has given its action and we have a response from the environment does this again leave the meta-environment.
In practice, we achieve this with a factory function. This takes in our base environment, and dynamically returns an environment that inherits from it:
def build_multiplayer_env(
env_name: type,
) -> type:
class MultiplayerEnvWrapper(env_name):
def __init__(
self,
agents: tuple[Optional[BaseAgent], BaseAgent, BaseAgent, BaseAgent],
):
# Agents is a tuple. If the tuple element is None, this is an
# active agent. Otherwise, if it is instance of another
# agent class, then this is a frozen agent, and is kept
# within the meta-environment.
self.agents = agents
super().__init__()
def reset(self, *, seed=None, options=None):
# Shuffle agents to put each in a random seat each game.
random_indexes = list(range(len(self.agents)))
random.shuffle(random_indexes)
agents_list = [self.agents[i] for i in random_indexes]
self.agents = tuple(agents_list)
return super().reset(seed=seed, options=options)
def step(self, action : int):
# When entering this function, it means that the active agent
# has sent an action and is asking for the next state.
while True:
# Update the internal state using the main environment.
# The step function in the main environment also handles
# incrementing the active player state variable.
state, reward, done, truncated, info = super().step(action)
if self.agents[self.state_h.active_player] is None:
# If the current agent is the active one, we return the
# state to the external agent.
return state, reward, done, truncated, info
else:
# Otherwise, we send the state to the next internal agent,
# get a returned action from them, and continue the loop.
agent = self.agents[self.state_h.active_player]
valid_actions = self.get_action_mask()
action = agent.get_action(
observation=state,
action_space_size=self.action_space.n, # type: ignore
valid_actions=valid_actions,
)
return MultiplayerEnvWrapper
This is then instantiated at the training stage like this:
agents = (
None,
FrozenAgent(model_path),
FrozenAgent(model_path),
FrozenAgent(model_path)
)
Multiplayer_env_class = build_multiplayer_env(PhotosynthesisEnv)
multiplayer_env = Multiplayer_env_class(agents=agents)
masked_env = ActionMasker(multiplayer_env, "get_action_mask")
monitored_env = Monitor(masked_env, filename = logs_folder + "monitor.csv")
The last two lines are two other built-in wrapper classes from SB3. The first allows us to designate certain actions as being invalid for the active agent (which we handle manually in MultiplayerEnvWrapper for the frozen agents), and the second logs the training data.
You can see here then that dynamically defining environment inheritance is a powerful and flexible tool when working in a highly object-oriented field such as RL.
Note also that we shuffle the agents each game. This stops the active agent from overfitting to a single seat.
This approach has the advantage of being very general and working for any agent type. Of course, in each episode, we only get one perspective, so training convergence rate will be a quarter of what it could be under a system that uses all four seats (such as the previously described buffer method for offline models), but for a game such as this that is not too big of an issue.
Multi-stage training
There is one more important factor to consider here. As mentioned before, the opponents are all frozen agents. This means that they do not improve as we undergo training (with model.learn(...)). When we do this we will eventually reach a limit. In the same way that an aspiring chess grandmaster will not achieve their desired level of skill by only playing against beginner players, the agent needs to train against tougher opponents in order to develop more subtle and rigorous strategies.
We therefore use the following training process. We start off by training the active agent against a random agent. This is an agent that simply randomly and uniformly selects from the list of valid actions.
After some condition is reached, either a predefined number of training timesteps, number of episodes, or performance level of the active agent, we take the saved weights of the active agent, freeze them, instantiate three frozen agents using these weights, and continue the training process, as shown in the image below. This self-play logic is what was used in systems like AlphaZero.
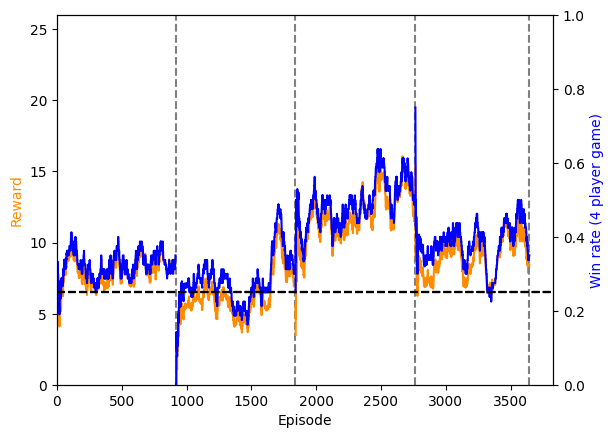
This results in a non-smooth and possibly discontinuous reward curve. Below is shown an example of this. Here, we see the win-rate of the active agent in blue, and the reward of the active agent in orange. The reward function being used here is $S$ when the active agent achieves a score of $S$ and comes in first place, and 0 if they do not come in first place.
As expected for a four-player game, the win-rate starts at 25%, and soon rises. The vertical dashed lines show the points where the active model weights are distributed to the frozen players.
Design diary
The current state of Photosynthesis AI is good enough to be functional, but there is a fair bit of work still to be done before it can be claimed to be the world’s first AI to achieve superhuman performance at the game. The main upcoming task is to containerise the training procedure to allow it to run in Google Cloud, perhaps in Vertex.
In upcoming blog posts, I will talk about:
- Different approaches to treating the six-fold symmetry of the game board.
- Some thoughts around the code architecture decisions I have made (i.e. focused around dataclasses).
- The benefits of redundancy in features.